#To install these packages remove the hash (#) characters in the lines below and run the cell. The ! tells jupyter to run a system command.
#! conda install xarray
#! conda install netcdf4
#! conda install cartopy Working with Gridded netCDF data and xarray
This lesson is based on the Lesson: working with netCDF data in Fabien Maussion’s Physics of the Climate System Course.
These lecture notes and exercises are licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) license.
You already learned how to use the basic features of the python language with the numpy and matplotlib libraries. The purpose of this lesson is to introduce you to the main tool that you will use for working with gridded data: xarray.
This is a dense lesson. Please do it entirely and try to remember its structure and content. This code will provide a template for your own code, and you can always come back to these examples when you’ll need them. I don’t expect you to understand all details, but I hope that you are going to get acquainted with the “xarray way” of manipulating multi-dimensional data. You will have to copy and adapt parts of the code below to complete the exercises.
Learning Objectives
- Describe netCDF files as self-describing data
- Understand how netCDF can be applied to big data
- Load netCDF datasets
- Select data by time and coordinates
- Perform aggregation operations
- Plot variables
NetCDF Files
In order to open and plot NetCDF files, you’ll need to install the xarray, cartopy, and netcdf4 packages: if you haven’t done so already, follow the installation instructions for our ISAT420 python environment that contains these packages.
As a quick fix, you can also install them directly using the code below (this will take some time).
Imports and options
First, let’s import the tools we need. Remember why we need to import our tools? If not, ask Dr. Gerken
# Import the tools we are going to need today:
import matplotlib.pyplot as plt # plotting library
import numpy as np # numerical library
import xarray as xr # netCDF library
import cartopy # Map projections libary
import cartopy.crs as ccrs # Projections list
from glob import glob
# Some defaults:
plt.rcParams['figure.figsize'] = (12, 5) # Default plot sizeThe Data
We will also be using an example of ERA5 Reanalysis data.
ERA5 (or European ReAnalysis v5) provides global, hourly estimates of atmospheric, ocean wave, and land-surface variables at a horizontal resolution of 31,km. Data is available from 1940 onwards both hourly and averaged to monthly.
Reanalysis in general are the fusion of observations with a global weather model to derive a homogenous, regular-best estimate output on a grid from station based observations.
ERA5 is produced by the European Center for Medium Range Weather Forecasting (ECMWF) and can be downloaded freely (account registration required).
I have placed the data files into the W8_Xarray_Gridded/Data directory.
Read the data
Most of today’s meteorological data is stored in the NetCDF format (*.nc). NetCDF files are binary files, which means that you can’t just open them in a text editor. You need a special reader for it. Nearly all the programming languages offer an interface to NetCDF. For this course we are going to use the xarray library to read the data:
Xarray commands are similar to pandas but not quite the same. To open a dataset ds we can use the .open_dataset() method.
Let’s start with having a look at the ERA5 file, I am providing.
# Here I downloaded the file in the "Data" folder which I placed in a folder close to this notebook
# The variable name "ds" stands for "dataset"
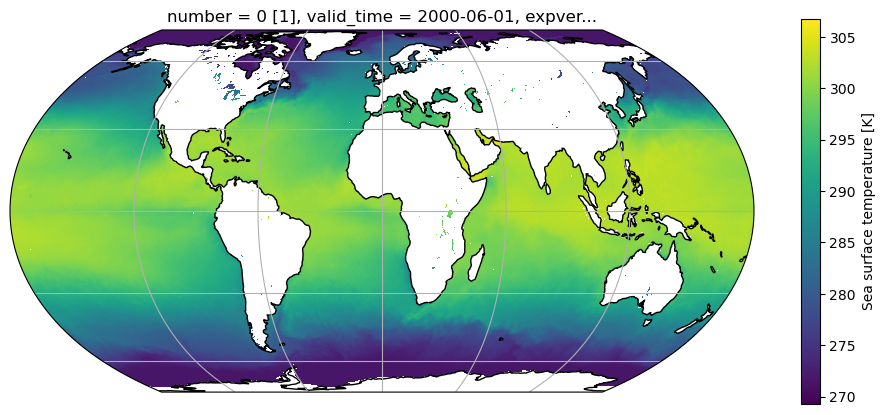
ds = xr.open_dataset(r'../data/reanalysis-era5-single-level-monthly-means_2000_T_Td_u_v_SST.nc', engine='netcdf4')# Lets see what we have:
ds<xarray.Dataset> Size: 249MB
Dimensions: (valid_time: 12, latitude: 721, longitude: 1440)
Coordinates:
* valid_time (valid_time) datetime64[ns] 96B 2000-01-01 ... 2000-12-01
expver (valid_time) <U4 192B ...
* latitude (latitude) float64 6kB 90.0 89.75 89.5 ... -89.5 -89.75 -90.0
* longitude (longitude) float64 12kB 0.0 0.25 0.5 0.75 ... 359.2 359.5 359.8
number int64 8B ...
Data variables:
u10 (valid_time, latitude, longitude) float32 50MB ...
v10 (valid_time, latitude, longitude) float32 50MB ...
d2m (valid_time, latitude, longitude) float32 50MB ...
t2m (valid_time, latitude, longitude) float32 50MB ...
sst (valid_time, latitude, longitude) float32 50MB ...
Attributes:
GRIB_centre: ecmf
GRIB_centreDescription: European Centre for Medium-Range Weather Forecasts
GRIB_subCentre: 0
Conventions: CF-1.7
institution: European Centre for Medium-Range Weather Forecasts
history: 2026-03-11T00:20 GRIB to CDM+CF via cfgrib-0.9.1...Each netcdf file has a data model, that is represented by xarray:
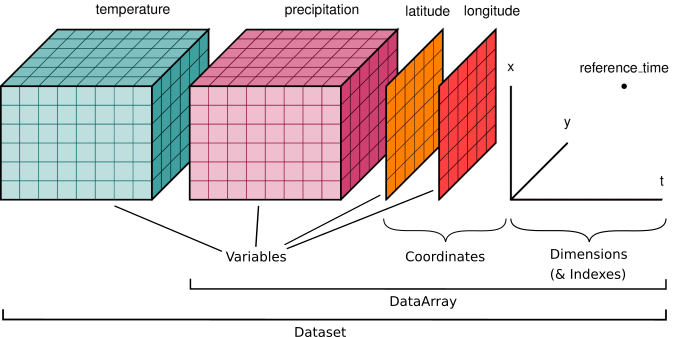
The NetCDF dataset is made up of various elements: Dimensions, Coordinates, Variables, Attributes:
- the dimensions specify the number of elements of each data coordinate, their names should be understandable and specific
- the attributes provide some information about the file (metadata)
- the variables contain the actual data. In our file there are five variables. All have the dimensions [time, latitude, longitude], so we can expect an array of size [12, 721, 1440]
- the coordinates locate the data in space and time
Working with big data
The entire ERA5 dataset is larger than 5 Petabytes. This is 5,000,000 GB. Your laptop has 8-16 GB of working memory (RAM) and even supercomputers cannot access more than a few TB of RAM.
Lazy execution
When loading a dataset in Pandas, you are always reading the entire dataset into memory. Xarray, in contrast uses lazy indexing by design. This means, when opening a dataset, the dataset is not actually read into memory, but Xarray learns its internal structure.
When we look into a variable, we can see the size, and the dtype of the underlying array, but not the actual values. This is because the values have not yet been loaded.
Xarray only loads data, when it is asked to produce an output such as printing a value to the screen or making a plot.
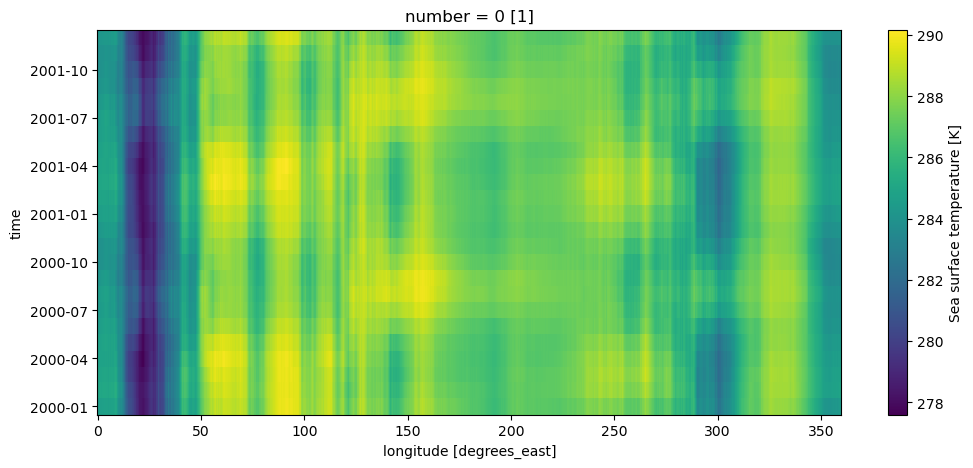
Loading multiple files
Since big data is distributed across many files, Xarray can also treat data that is spread across multiple files as a single dataset. This is done by passing a list of files to the .open_mfdataset method.
files = glob(r'../Data/*.nc')
files['../Data\\reanalysis-era5-single-level-monthly-means_2000_T_Td_u_v_SST.nc',
'../Data\\reanalysis-era5-single-level-monthly-means_2001_T_Td_u_v_SST.nc']ds = xr.open_mfdataset(files, engine='netcdf4')
dslatitude
(latitude)
float64
90.0 89.75 89.5 ... -89.75 -90.0
- units :
- degrees_north
- standard_name :
- latitude
- long_name :
- latitude
- stored_direction :
- decreasing
array([ 90. , 89.75, 89.5 , ..., -89.5 , -89.75, -90. ], shape=(721,))
longitude
(longitude)
float64
0.0 0.25 0.5 ... 359.2 359.5 359.8
- units :
- degrees_east
- standard_name :
- longitude
- long_name :
- longitude
array([0.0000e+00, 2.5000e-01, 5.0000e-01, ..., 3.5925e+02, 3.5950e+02,
3.5975e+02], shape=(1440,))number
()
int64
0
- long_name :
- ensemble member numerical id
- units :
- 1
- standard_name :
- realization
array(0)
- u10(valid_time, latitude, longitude)float32dask.array<chunksize=(6, 361, 720), meta=np.ndarray>
- GRIB_paramId :
- 165
- GRIB_dataType :
- an
- GRIB_numberOfPoints :
- 1038240
- GRIB_typeOfLevel :
- surface
- GRIB_stepUnits :
- 1
- GRIB_stepType :
- avgua
- GRIB_gridType :
- regular_ll
- GRIB_uvRelativeToGrid :
- 0
- GRIB_NV :
- 0
- GRIB_Nx :
- 1440
- GRIB_Ny :
- 721
- GRIB_cfName :
- unknown
- GRIB_cfVarName :
- u10
- GRIB_gridDefinitionDescription :
- Latitude/Longitude Grid
- GRIB_iDirectionIncrementInDegrees :
- 0.25
- GRIB_iScansNegatively :
- 0
- GRIB_jDirectionIncrementInDegrees :
- 0.25
- GRIB_jPointsAreConsecutive :
- 0
- GRIB_jScansPositively :
- 0
- GRIB_latitudeOfFirstGridPointInDegrees :
- 90.0
- GRIB_latitudeOfLastGridPointInDegrees :
- -90.0
- GRIB_longitudeOfFirstGridPointInDegrees :
- 0.0
- GRIB_longitudeOfLastGridPointInDegrees :
- 359.75
- GRIB_missingValue :
- 3.4028234663852886e+38
- GRIB_name :
- 10 metre U wind component
- GRIB_shortName :
- 10u
- GRIB_totalNumber :
- 0
- GRIB_units :
- m s**-1
- long_name :
- 10 metre U wind component
- units :
- m s**-1
- standard_name :
- unknown
- GRIB_surface :
- 0.0
Array Chunk Bytes 95.05 MiB 5.95 MiB Shape (24, 721, 1440) (6, 361, 720) Dask graph 16 chunks in 5 graph layers Data type float32 numpy.ndarray - v10(valid_time, latitude, longitude)float32dask.array<chunksize=(6, 361, 720), meta=np.ndarray>
- GRIB_paramId :
- 166
- GRIB_dataType :
- an
- GRIB_numberOfPoints :
- 1038240
- GRIB_typeOfLevel :
- surface
- GRIB_stepUnits :
- 1
- GRIB_stepType :
- avgua
- GRIB_gridType :
- regular_ll
- GRIB_uvRelativeToGrid :
- 0
- GRIB_NV :
- 0
- GRIB_Nx :
- 1440
- GRIB_Ny :
- 721
- GRIB_cfName :
- unknown
- GRIB_cfVarName :
- v10
- GRIB_gridDefinitionDescription :
- Latitude/Longitude Grid
- GRIB_iDirectionIncrementInDegrees :
- 0.25
- GRIB_iScansNegatively :
- 0
- GRIB_jDirectionIncrementInDegrees :
- 0.25
- GRIB_jPointsAreConsecutive :
- 0
- GRIB_jScansPositively :
- 0
- GRIB_latitudeOfFirstGridPointInDegrees :
- 90.0
- GRIB_latitudeOfLastGridPointInDegrees :
- -90.0
- GRIB_longitudeOfFirstGridPointInDegrees :
- 0.0
- GRIB_longitudeOfLastGridPointInDegrees :
- 359.75
- GRIB_missingValue :
- 3.4028234663852886e+38
- GRIB_name :
- 10 metre V wind component
- GRIB_shortName :
- 10v
- GRIB_totalNumber :
- 0
- GRIB_units :
- m s**-1
- long_name :
- 10 metre V wind component
- units :
- m s**-1
- standard_name :
- unknown
- GRIB_surface :
- 0.0
Array Chunk Bytes 95.05 MiB 5.95 MiB Shape (24, 721, 1440) (6, 361, 720) Dask graph 16 chunks in 5 graph layers Data type float32 numpy.ndarray - d2m(valid_time, latitude, longitude)float32dask.array<chunksize=(6, 361, 720), meta=np.ndarray>
- GRIB_paramId :
- 168
- GRIB_dataType :
- an
- GRIB_numberOfPoints :
- 1038240
- GRIB_typeOfLevel :
- surface
- GRIB_stepUnits :
- 1
- GRIB_stepType :
- avgua
- GRIB_gridType :
- regular_ll
- GRIB_uvRelativeToGrid :
- 0
- GRIB_NV :
- 0
- GRIB_Nx :
- 1440
- GRIB_Ny :
- 721
- GRIB_cfName :
- unknown
- GRIB_cfVarName :
- d2m
- GRIB_gridDefinitionDescription :
- Latitude/Longitude Grid
- GRIB_iDirectionIncrementInDegrees :
- 0.25
- GRIB_iScansNegatively :
- 0
- GRIB_jDirectionIncrementInDegrees :
- 0.25
- GRIB_jPointsAreConsecutive :
- 0
- GRIB_jScansPositively :
- 0
- GRIB_latitudeOfFirstGridPointInDegrees :
- 90.0
- GRIB_latitudeOfLastGridPointInDegrees :
- -90.0
- GRIB_longitudeOfFirstGridPointInDegrees :
- 0.0
- GRIB_longitudeOfLastGridPointInDegrees :
- 359.75
- GRIB_missingValue :
- 3.4028234663852886e+38
- GRIB_name :
- 2 metre dewpoint temperature
- GRIB_shortName :
- 2d
- GRIB_totalNumber :
- 0
- GRIB_units :
- K
- long_name :
- 2 metre dewpoint temperature
- units :
- K
- standard_name :
- unknown
- GRIB_surface :
- 0.0
Array Chunk Bytes 95.05 MiB 5.95 MiB Shape (24, 721, 1440) (6, 361, 720) Dask graph 16 chunks in 5 graph layers Data type float32 numpy.ndarray - t2m(valid_time, latitude, longitude)float32dask.array<chunksize=(6, 361, 720), meta=np.ndarray>
- GRIB_paramId :
- 167
- GRIB_dataType :
- an
- GRIB_numberOfPoints :
- 1038240
- GRIB_typeOfLevel :
- surface
- GRIB_stepUnits :
- 1
- GRIB_stepType :
- avgua
- GRIB_gridType :
- regular_ll
- GRIB_uvRelativeToGrid :
- 0
- GRIB_NV :
- 0
- GRIB_Nx :
- 1440
- GRIB_Ny :
- 721
- GRIB_cfName :
- unknown
- GRIB_cfVarName :
- t2m
- GRIB_gridDefinitionDescription :
- Latitude/Longitude Grid
- GRIB_iDirectionIncrementInDegrees :
- 0.25
- GRIB_iScansNegatively :
- 0
- GRIB_jDirectionIncrementInDegrees :
- 0.25
- GRIB_jPointsAreConsecutive :
- 0
- GRIB_jScansPositively :
- 0
- GRIB_latitudeOfFirstGridPointInDegrees :
- 90.0
- GRIB_latitudeOfLastGridPointInDegrees :
- -90.0
- GRIB_longitudeOfFirstGridPointInDegrees :
- 0.0
- GRIB_longitudeOfLastGridPointInDegrees :
- 359.75
- GRIB_missingValue :
- 3.4028234663852886e+38
- GRIB_name :
- 2 metre temperature
- GRIB_shortName :
- 2t
- GRIB_totalNumber :
- 0
- GRIB_units :
- K
- long_name :
- 2 metre temperature
- units :
- K
- standard_name :
- unknown
- GRIB_surface :
- 0.0
Array Chunk Bytes 95.05 MiB 5.95 MiB Shape (24, 721, 1440) (6, 361, 720) Dask graph 16 chunks in 5 graph layers Data type float32 numpy.ndarray - sst(valid_time, latitude, longitude)float32dask.array<chunksize=(6, 361, 720), meta=np.ndarray>
- GRIB_paramId :
- 34
- GRIB_dataType :
- an
- GRIB_numberOfPoints :
- 1038240
- GRIB_typeOfLevel :
- surface
- GRIB_stepUnits :
- 1
- GRIB_stepType :
- avgua
- GRIB_gridType :
- regular_ll
- GRIB_uvRelativeToGrid :
- 0
- GRIB_NV :
- 0
- GRIB_Nx :
- 1440
- GRIB_Ny :
- 721
- GRIB_cfName :
- unknown
- GRIB_cfVarName :
- sst
- GRIB_gridDefinitionDescription :
- Latitude/Longitude Grid
- GRIB_iDirectionIncrementInDegrees :
- 0.25
- GRIB_iScansNegatively :
- 0
- GRIB_jDirectionIncrementInDegrees :
- 0.25
- GRIB_jPointsAreConsecutive :
- 0
- GRIB_jScansPositively :
- 0
- GRIB_latitudeOfFirstGridPointInDegrees :
- 90.0
- GRIB_latitudeOfLastGridPointInDegrees :
- -90.0
- GRIB_longitudeOfFirstGridPointInDegrees :
- 0.0
- GRIB_longitudeOfLastGridPointInDegrees :
- 359.75
- GRIB_missingValue :
- 3.4028234663852886e+38
- GRIB_name :
- Sea surface temperature
- GRIB_shortName :
- sst
- GRIB_units :
- K
- long_name :
- Sea surface temperature
- units :
- K
- standard_name :
- unknown
- GRIB_surface :
- 0.0
Array Chunk Bytes 95.05 MiB 5.95 MiB Shape (24, 721, 1440) (6, 361, 720) Dask graph 16 chunks in 5 graph layers Data type float32 numpy.ndarray
- GRIB_centre :
- ecmf
- GRIB_centreDescription :
- European Centre for Medium-Range Weather Forecasts
- GRIB_subCentre :
- 0
- Conventions :
- CF-1.7
- institution :
- European Centre for Medium-Range Weather Forecasts
- history :
- 2026-03-11T00:20 GRIB to CDM+CF via cfgrib-0.9.15.1/ecCodes-2.42.0 with {"source": "tmp4g3rqpp6/data.grib", "filter_by_keys": {"stream": ["mnth"], "stepType": ["avgua"]}, "encode_cf": ["parameter", "time", "geography", "vertical"]}